其实rabbitMQ的官网的使用文档已经写的非常好了,有各种语言使用的举例,以及各种使用方式。
rabbitMQ是什么
RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现,官网地址:http://www.rabbitmq.com。RabbitMQ作为一个消息代理,主要负责接收、存储和转发消息, 它提供了可靠的消息机制和灵活的消息路由,并支持消息集群和分布式部署,常用于应用解耦,耗时任务队列,流量削锋等场景。本系列文章将系统介绍RabbitMQ的工作机制,代码驱动和集群配置,本篇主要介绍RabbitMQ中一些基本概念:
上图是RabbitMQ的一个基本结构,生产者Producer和消费者Consumer都是RabbitMQ的客户端,Producer负责发送消息,Consumer负责消费消息。
**接下来我们结合这张图来理解RabbitMQ的一些概念:
- Broker(Server):接受客户端连接,实现AMQP消息队列和路由功能的进程,我们可以把Broker叫做RabbitMQ服务器。
- Virtual Host:一个虚拟概念,一个Virtual Host里面可以有若干个Exchange和Queue,主要用于权限控制,隔离应用。如应用程序A使用VhostA,应用程序B使用VhostB,那么我们在VhostA中只存放应用程序A的exchange,queue和消息,应用程序A的用户只能访问VhostA,不能访问VhostB中的数据。
- Exchange:接受生产者发送的消息,并根据Binding规则将消息路由给服务器中的队列。ExchangeType决定了Exchange路由消息的行为,例如,在RabbitMQ中,ExchangeType有Direct、Fanout、Topic和Header四种,不同类型的Exchange路由规则是不一样的(这些以后会详细介绍)。
- Queue:消息队列,用于存储还未被消费者消费的消息,队列是先进先出的,默认情况下先存储的消息先被处理。
- Message:就是消息,由Header和Body组成,Header是由生产者添加的各种属性的集合,包括Message是否被持久化、由哪个Message Queue接受、优先级是多少等,Body是真正传输的数据,内容格式为byte[]。
- Connection:连接,对于RabbitMQ而言,其实就是一个位于客户端和Broker之间的TCP连接。
- Channel:信道,仅仅创建了客户端到Broker之间的连接Connection后,客户端还是不能发送消息的。需要在Connection的基础上创建Channel,AMQP协议规定只有通过Channel才能执行AMQP的命令,一个Connection可以包含多个Channel。之所以需要Channel,是因为TCP连接的建立和释放都是十分昂贵的。
安装注意
安装rabbitMQ之前需要先安装erlang。
rabbit的默认管理地址是15672
rabbit的访问地址是5672
centos下安装rabbitMQ:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#安装socat
yum install socat
#安装erlang
curl -s https://packagecloud.io/install/repositories/rabbitmq/erlang/script.rpm.sh | sudo bash
yum -y install erlang
#安装rabbitmq-server
curl -s https://packagecloud.io/install/repositories/rabbitmq/rabbitmq-server/script.rpm.sh | sudo bash
yum -y install rabbitmq-server
#启动rabbitmq服务
systemctl start rabbitmq-server
#添加web管理插件
rabbitmq-plugins enable rabbitmq_management
操作:1
2
3
4
5
6
7
8#启动RabbitMQ服务
systemctl start rabbitmq-server
#停止RabbitMQ服务
systemctl stop rabbitmq-server
#查看RabbitMQ运行状态
systemctl status rabbitmq-server
#重启RabbitMQ服务
systemctl restart rabbitmq-server
SpringBoot中使用RabbitMQ
pom.xml:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
application.properties:1
2
3
4
5
6
7spring.application.name=springboot-rabbitmq
spring.rabbitmq.host=127.0.0.1
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
spring.rabbitmq.publisher-confirms=true
spring.rabbitmq.virtual-host=/
简单队列
简单队列:创建两个Console应用,一个作为发送消息的生产者(Producer),一个作为接受消息的消费者(Consumer),生产者向队列写入消息,消费者接受这条消息,结构如下: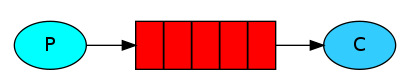
一个生产者生产消息,如果有新的消息在队列中,消费者就会监听到并且可以拿到消息内容,从而消费消息
工作队列
而且我们实际开发,生产者发送消息是毫不费力的,而消费者一般是要跟业务相结合,消费者接收到消息之后需要处理,可能需要花费比较多的时间,这时候队列就会积压很多消息。所以我们可以让一个消息队列有多个消费者。
工作队列可以有多种消费模式:
轮询
顾名思义就是多个消费者逐一消费
公平分发
能者多劳,消费者每次处理完一个消息,才反馈给队列,然后队列才允许它消费下一个下消息。使用公布分发,必须关闭ack设置
exchange(交换器)
在消费者到产生的消息到队列中间,为了更好的分发消息可以加一层exchange(交换器):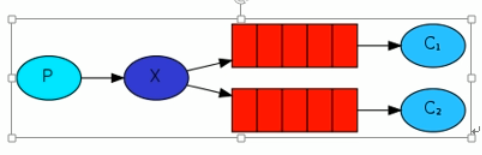
解读:
1.一个生成者,多个消费者
2.每个消费者,都有自己的队列
3.生成者没有直接把消息发送到队列,而是发到了交换机,转发器(exchange)
4.每个队列都要绑定到交换机上,需要指定一个routerKey
5.生产者发送的消息,经过交换机,到达队列,就能实现一个消息被多个消费者消费
而交换机可以有多种工作方式
fanout
1.一方面接收生产者的消息,另一方面是向队列推送消息
fanout:不处理路由建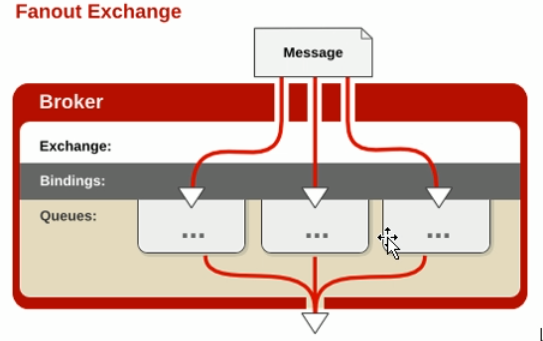
direct
direct:完全匹配路由键
生产者生产一个消息需要指定路由键: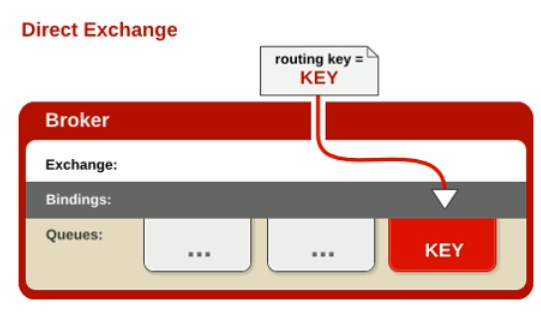
路由模式: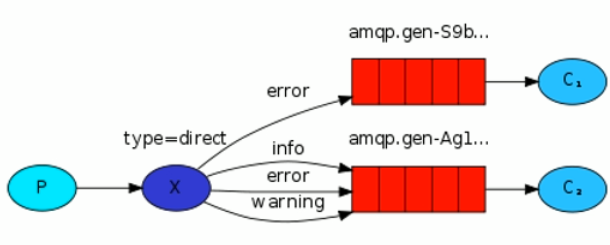
如果生产者发送的消息带有error建 则会发送消息到队列C1和C2
如果生产者发送的消息带有info\warning建 则会发送消息到队列 C2
topic
topic:将路由建和某个模式匹配
此时队列需要绑定要一个模式上。符号“#”匹配一个或多个词,符号“”匹配一个词。
因此“audit.#”能够匹配到 “audit.irs.corporate”,但是“audit.” 只会匹配到“audit.irs”。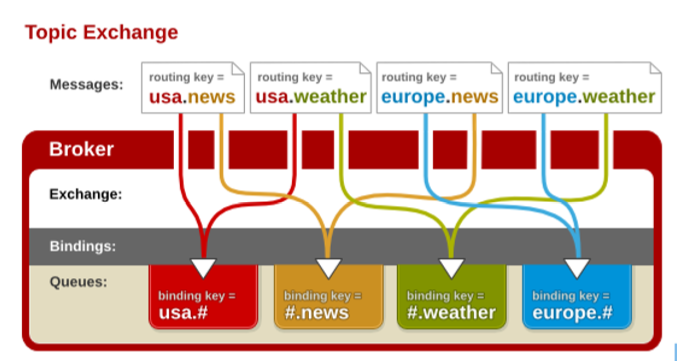
RabbitMQ消息确认机制(事务+confirm)
在rabbitmq中我们可以通过持久化数据解决rabbitMQ服务器异常的数据丢包问题,(即 Rabbit 服务器不会反馈任何消息给生产者),也就是默认的情况下是不知道消息有没有 正确到达:
问题:生产者将消息发送出去之后,消息到底有没有到达rabbitMQ服务器,默认情况是不知道的
AMQP协议实现了事务机制
AMQP事务机制:
txSelect txCommit txRollback
txSelect:用户将当前channel设置成transation模式
txCommit:用于提交事务
txRollback:回滚事务
上面我们介绍了 RabbitMQ 可能会遇到的一个问题,即生成者不知道消息是否真正到达 broker,随后通过 AMQP 协议层面为我们提供了事务机制解决了这个问题,但是采用事务机制实现会降低 RabbitMQ 的消息吞吐量,那么有没有更加高效的解决方式呢?答案是采用 Confirm 模式。
Confirm模式(异步的)
producer 端 confirm 模式的实现原理
生产者将信道设置成 confirm 模式,一旦信道进入 confirm 模式,所有在该信道上面发布的消息都会被指派一个唯 一的 ID(从 1 开始),一旦消息被投递到所有匹配的队列之后,broker 就会发送一个确认给生产者(包含消息的唯一 ID) ,这就使得生产者知道消息已经正确到达目的队列了,如果消息和队列是可持久化的,那么确认消息会将消息写 入磁盘之后发出,broker 回传给生产者的确认消息中 deliver-tag 域包含了确认消息的序列号,此外 broker 也可以设 置 basic.ack 的 multiple 域,表示到这个序列号之前的所有消息都已经得到了处理。
confirm模式最大的好处在于他是异步的,一旦发布一条消息,生产者应用程序就可以在等信道返回确认的同时继 续发送下一条消息,当消息最终得到确认之后,生产者应用便可以通过回调方法来处理该确认消息,如果 RabbitMQ 因为自身内部错误导致消息丢失,就会发送一条 nack 消息,生产者应用程序同样可以在回调方法中处 理该 nack 消息。